


Platform Event Trap (PET) is a hardware-generated alert used in server environments to report critical system events such as overheating processors, failing fans, or power supply issues. It works through the Intelligent Platform Management Interface standard and sends notifications to monitoring platforms using Simple Network Management Protocol traps. Because it is triggered directly by hardware sensors, the alert system continues to function even when the operating system stops responding.
- Understanding the Core Idea Behind Hardware Event Notifications
- How the IPMI Management Standard Enables Server Monitoring
- How SNMP Trap Notifications Deliver Hardware Alerts
- Typical Hardware Conditions That Generate Alerts
- Key Components in Hardware Monitoring
- Why Hardware Alert Systems Are Essential in Enterprise IT
- Best Practices for Implementing Hardware Event Monitoring
- FAQs
- Conclusion
In simple terms, Platform Event Trap technology allows administrators to detect serious hardware problems in real time. This independent monitoring capability improves infrastructure reliability, helps prevent downtime, and enables faster troubleshooting in data centers, enterprise servers, and cloud computing environments.
Understanding the Core Idea Behind Hardware Event Notifications
In modern server architecture, hardware health monitoring is handled by specialized components embedded in the motherboard. One of the most important components involved in sending a Platform Event Trap is the Baseboard Management Controller, commonly called BMC.
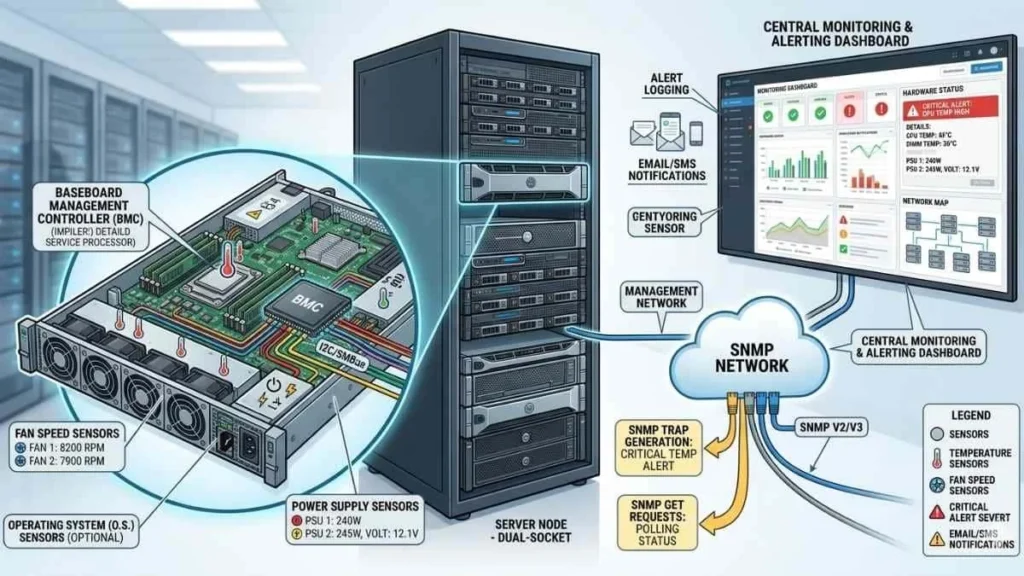
This controller constantly reads information from system sensors such as temperature monitors, voltage regulators, and fan speed indicators. When one of these sensors detects a reading outside its safe range, the management controller records the incident and generates an alert message.
How the IPMI Management Standard Enables Server Monitoring
Within an IPMI environment, several functions work together to monitor hardware health. Sensors gather information about different components inside the server chassis. These readings are stored in the system event log whenever a threshold is exceeded.
When a significant hardware condition occurs, the server management controller generates a Platform Event Trap notification. This message is then transmitted through network monitoring channels to inform administrators about the problem.
This mechanism forms the foundation of out-of-band management. Administrators can diagnose hardware conditions remotely even if the server itself is offline.
How SNMP Trap Notifications Deliver Hardware Alerts
The alert process follows a structured communication flow:
• A hardware sensor detects an abnormal condition
• The management controller logs the event in the system event log
• The controller generates a Platform Event Trap message
• The message is transmitted as an SNMP trap to a monitoring server
• The monitoring platform processes the alert and notifies administrators
Typical Hardware Conditions That Generate Alerts
Server hardware contains many sensors designed to maintain safe operating conditions. When these sensors detect irregularities, the monitoring controller triggers a Platform Event Trap alert. Below are the most common hardware conditions that generate PET notifications:
1. CPU and Motherboard Temperature Issues
Excessive heat in processors or the motherboard can lead to system instability. PET alerts are triggered when temperature thresholds are exceeded, allowing administrators to take immediate action to prevent overheating.
2. Cooling Fan Malfunctions
Cooling fans maintain airflow in servers. Alerts are generated if a fan stops spinning, slows down below acceptable limits, or fails altogether. Early warnings prevent thermal damage to critical components.
3. Power Supply Failures
Redundant power supplies provide reliability, but a failure in one unit can compromise system stability. PET alerts notify administrators about voltage inconsistencies or total power supply failure.
4. Memory and CPU Error Detection
Certain memory modules and CPUs can detect internal faults or errors. PET alerts report these faults promptly, enabling proactive maintenance before performance degradation occurs.
Key Components in Hardware Monitoring
| Component | Function in Server Monitoring | Role in Hardware Alerts |
| Baseboard Management Controller | Dedicated management processor | Generates and sends alerts |
| Temperature Sensors | Measure internal heat levels | Detect overheating conditions |
| Fan Sensors | Track cooling system performance | Identify cooling failures |
| Power Supply Sensors | Monitor electrical stability | Detect power disruptions |
| System Event Log | Stores recorded hardware events | Maintains historical alert data |
Why Hardware Alert Systems Are Essential in Enterprise IT
Reliable infrastructure monitoring is critical for organizations that rely on digital services. Hardware alert technologies like Platform Event Trap provide early warnings that help prevent system failures.

In large data centers, thousands of servers operate simultaneously. Without automated alert systems, detecting hardware failures quickly would be extremely difficult. PET alerts make it possible for monitoring platforms to detect faults the moment they occur.
Best Practices for Implementing Hardware Event Monitoring
Organizations can improve infrastructure reliability by following proven monitoring strategies.
• Enable all hardware sensors and verify threshold settings
• Integrate monitoring alerts with centralized infrastructure tools
• Test alert delivery regularly to ensure notifications are working
By following these practices, organizations create a proactive monitoring environment that identifies hardware issues early.
FAQs
Can hardware alerts work when a server operating system is not running?
Yes. The monitoring system works independently through the server management controller.
Do hardware alerts require special monitoring software?
Most enterprise monitoring platforms support SNMP traps, so specialized tools are usually not required.
Are hardware monitoring alerts useful for small server environments?
Yes. Even smaller infrastructures benefit from early hardware failure detection.
Conclusion
Platform Event Trap plays an important role in modern infrastructure monitoring because it enables hardware components to report problems instantly. Since the alert mechanism operates independently from the operating system, administrators can receive notifications even during system crashes or severe hardware failures.
This capability makes the Platform Event Trap system an essential part of enterprise server management. By combining IPMI-based monitoring with SNMP alert delivery, organizations gain a powerful method for detecting hardware issues quickly and maintaining reliable digital services.





